[오승상 강화학습] 01. DRL Introduction
[오승상 강화학습] 01. DRL Introduction
1. 목차

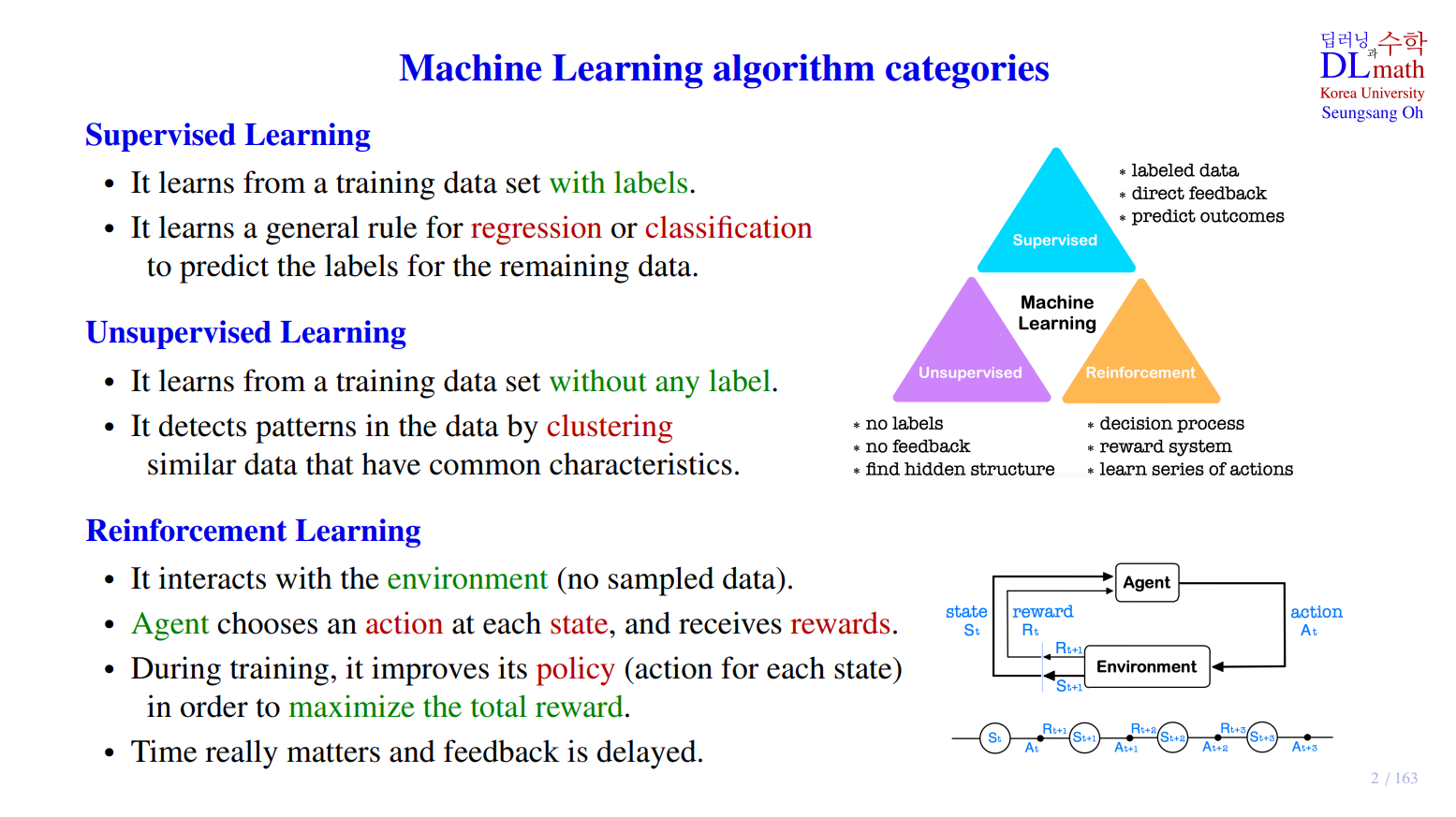
2. Machine Learning algorithm categories
2-1. 인공지능(AI, Artificial Intelligence)
- 인간의 학습, 추론, 문제 해결 능력 등을 컴퓨터나 기계가 인공적으로 구현하는 기술
2-2. 기계학습(ML, Machine Learning)
- 컴퓨터가 사람이 직접 만든 명시적인 규칙을 일일이 프로그래밍하지 않고도, 방대한 데이터를 통해 스스로 패턴을 학습하고 예측이나 결정을 내리게하는 기술
- 인공지능(AI)의 하위 분야
2-3. 지도학습(Supervised Learning)
- label이 지정된 training dataset을 통해 학습한다.
- 회귀(regression) 또는 분류(classification)를 위한 일반적인 규칙을 학습하여 나머지 데이터의 label을 예측한다.
- labeled data
- direct feedback
- predict outcomes
2-4. 비지도학습(Unsupervised Learning)
- label이 없는 training dataset을 통해 학습한다.
- 이 방법은 공통된 특성을 가진 유사한 데이터들을 클러스터링(clustering, 군집화)하여 데이터 내의 패턴을 식별한다.
- no labels
- no feedback
- find hidden structure
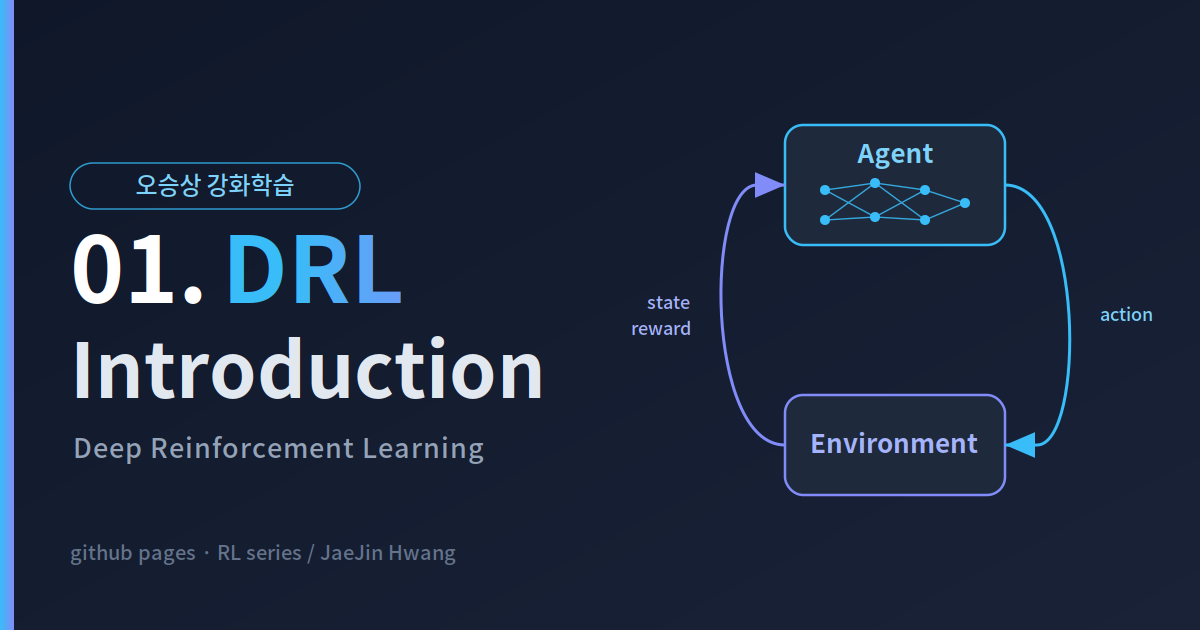
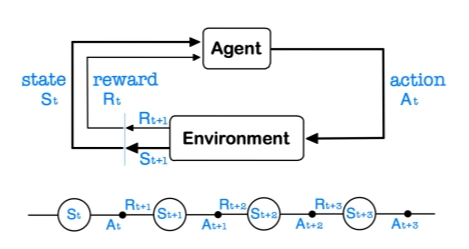
2-5. 강화학습(RL, Reinforcement Learning)
- 환경(environment)과 상호작용(interact) 한다.
- 에이전트(agent)는 각 상태(state)에서 행동(action)을 선택하고 보상(reward)을 받는다.
- 각각의 action에 대한 reward를 얻은 후에 policy를 업데이트하기 때문에 feedback에 대한 delay가 존재한다.
- decision process
- reward system
- learn series of actions
강화학습은 다음과 같이 크게 2단계로 나눌 수 있다.
Policy evaluation
total reward를 계산하는 방법Policy improvement
total reward를 maximize 하는 방향으로 policy(각 state에 대한 action)을 계산하는 방법
⇒ 강화학습은 위 두 단계를 반복적으로 수행함으로써 optimal policy를 계산해 나간다.
3. Deep Learning

Machine Learning
- 머신러닝(ML)에서 인간은 ‘특징(feature)’ 간의 패턴과 상관관계를 직접 추출해야 한다.
- 추출해야 할 모든 특징을 파악하기 어렵기 때문에 이러한 feature engineering(feature extraction or data preprocessing) 과정은 대개 시간이 많이 소요되고, 과도하게 구체화 되거나(over-specified) 모든 특징들을 다 찾아낼 수 없다(incomplete).
- 복잡한 문제 보다는 상대적으로 단순한 문제들을 처리할 때 유용하다.
Deep Learning
- 딥러닝(DL)은 Deep Neural Network(many layer) 구조를 활용하고, 방대한 양의 원시 입력 데이터에서 단계적으로 고차원 특징을 추출하기 때문에 automatic feature engineering이 이루어진다.
- 학습해야 할 파라미터 수가 ML에 비해 매우 많기 때문에 입력 데이터 양이 많아질수록 학습가능한 파라미터(learnable network parameters)의 정확도가 높아지게 된다.
- 또한 역전파(backpropagation)를 사용하여 기울기(gradient)를 효율적으로 계산하고, 수백만 개의 네트워크 파라미터를 업데이트하는 종단간(end-to-end) 학습 방식이므로, 도메인 지식에 대한 의존도를 크게 줄여준다.
- 대표적인 DNN 모델로는 CNN(computer vision), RNN(language model), GAN(generative model) 등이 있다.
4. Deep Reinforcement Learning

DL 발전에 도움을 준 핵심 요소
- 빅데이터, 강력한 연산 능력 그리고 새로운 딥러닝 알고리즘을 바탕으로 DRL은 게임, 로봇공학, 금융, 자율주행 등 다양한 분야에서 큰 발전을 이루었습니다.
차원의 저주(curse of dimensionality)
- 로봇공학 문제에서 상태 공간(state space)은 상태 변수(state variables)의 수에 따라 기하급수적으로(exponentially) 증가하게 된다.
- e.g. 로봇 관절 하나의 가동 범위를 1~90도 라고 할 때, 관절 하나 당 state는 90가지가 나오게 되고, 로봇에 사용되는 관절이 10개 있다면 state는 $90^{10}$ 가지가 나오게 된다.
- RL에 DL을 적용함으로써, 고차원 데이터(이미지, 텍스트, 오디오)의 저차원 특징을 자동으로 찾아낸다.
DRL의 두 가지 혁신
- DQN (DeepMind 2013) : 이미지 픽셀을 분석하여 아타리 게임(Atari games)을 초인적인 수준으로 플레이함
- AlphaGo (Google DeepMind 2016) : CNN + RL을 적용하여 이세돌 9단과 바둑 경기 진행 (4:1 AlphaGo win)
David Silver의 견해
- 앞으로의 인공지능은 DL과 RL이 결합된 형태로 나아갈 것이다.
\(Artificial \ Intelligence = Deep \ Learning \ + \ Reinforcement \ Learning\)
Reference
https://www.youtube.com/watch?v=HXIbrL-glpU&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=2
This post is licensed under CC BY 4.0 by the author.