[오승상 강화학습] 02. Markov property
1. Grid world example
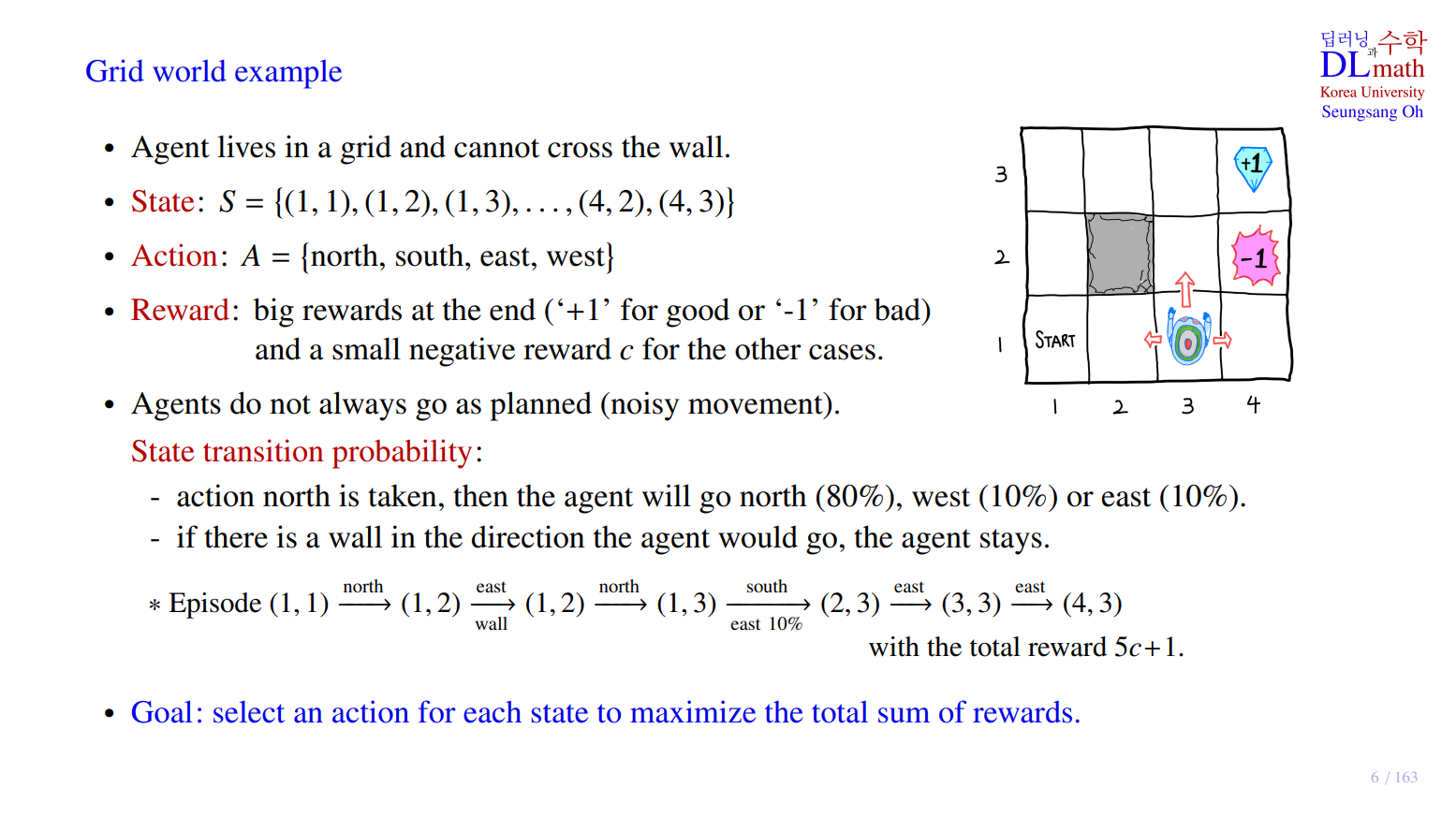
Grid world example
- start 지점에서 출발해서 action을 취하며 한 칸씩 이동
- (2,2) 지점에는 벽이 존재하여 이동할 수 없음
- (4,3) 또는 (4,2) 위치에 도달하게 되면 게임 종료
- robot이 최대한 많은 reward를 획득한 채로 게임을 종료하는 것이 목표
1-1. 에이전트(Agent)
- 강화학습을 통해 스스로 학습하는 컴퓨터 (학습의 주체)
- 위 grid world example에서 agent는 robot에 해당한다.
1-2. 상태(State)
- $ S = \left\lbrace (1,1),(1,2), \cdots, (4,2),(4,3) \right\rbrace$
- 위 grid world example에서는 (2,2)를 제외한 총 11개의 state가 존재한다.
1-3. 행동(Action)
- $A = \left\lbrace north, \ south, \ east, \ west \right\rbrace$
- 위 grid world example에서는 agent가 동서남북 방향으로 한 칸씩 이동하는 것을 의미한다.
1-4. 보상(Reward)
- agent에게 reward를 부여하고, reward가 maximize 되는 방향으로 학습을 진행
- big reward : (4,3) 위치에서 마치게 되면 승점 +1 / (4,2) 위치에서 마치게 되면 벌점 -1
- small negative reward( $c$ ) : 한 번 action을 취할 때 마다 소량의 감점 부여
1-5. small negative reward가 필요한 이유
- 의미없는 action을 줄이고, 게임이 길어지는 것을 방지하기 위해서 필요하다.
Agent는 항상 계획한대로 움직이지 않는다. (noise movement)
1-6. 상태 전이 확률(State transition probability)
- 만약, north로 이동하는 action을 취하면 agent는 north(80%), west(10%), east(10%)로 이동할 확률을 가진다. 이를 통해서 action을 취했을 때 무작위성이 작용된다는 것을 알 수 있다.
1-7. 에피소드(Episode)
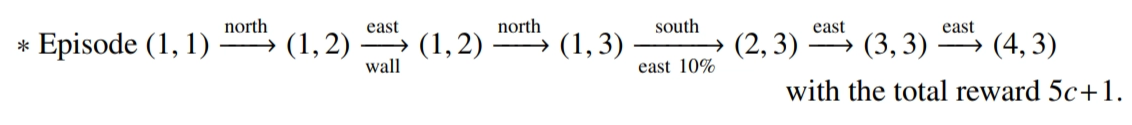
- grid world example에서 게임을 한 번 진행하는 것을 의미
- 벽쪽으로 action을 취할 경우 제자리에 머문다고 가정
- 위 episode의 경우 total reward는 $5c+1$
1-7. 정책(Policy)
- 각 state 마다 action을 선택하는 방법
- policy를 통해 각 episode에서 얻어지는 reward가 달라진다.
⇒ Optimal policy : total sum of reward 를 maximize하는 policy
1-8. 강화학습의 목표
- episode를 진행하는 동안에 각 state 마다 최적의 action을 선택해서 total reward를 maximize 하는 것
- 즉, Optimal policy를 찾는 것
2. Action in Grid world
State transition probability에 대해서는 두 가지 방안이 있을 수 있다.
이는 action을 적용하는 방법론에 대해 다룬다. 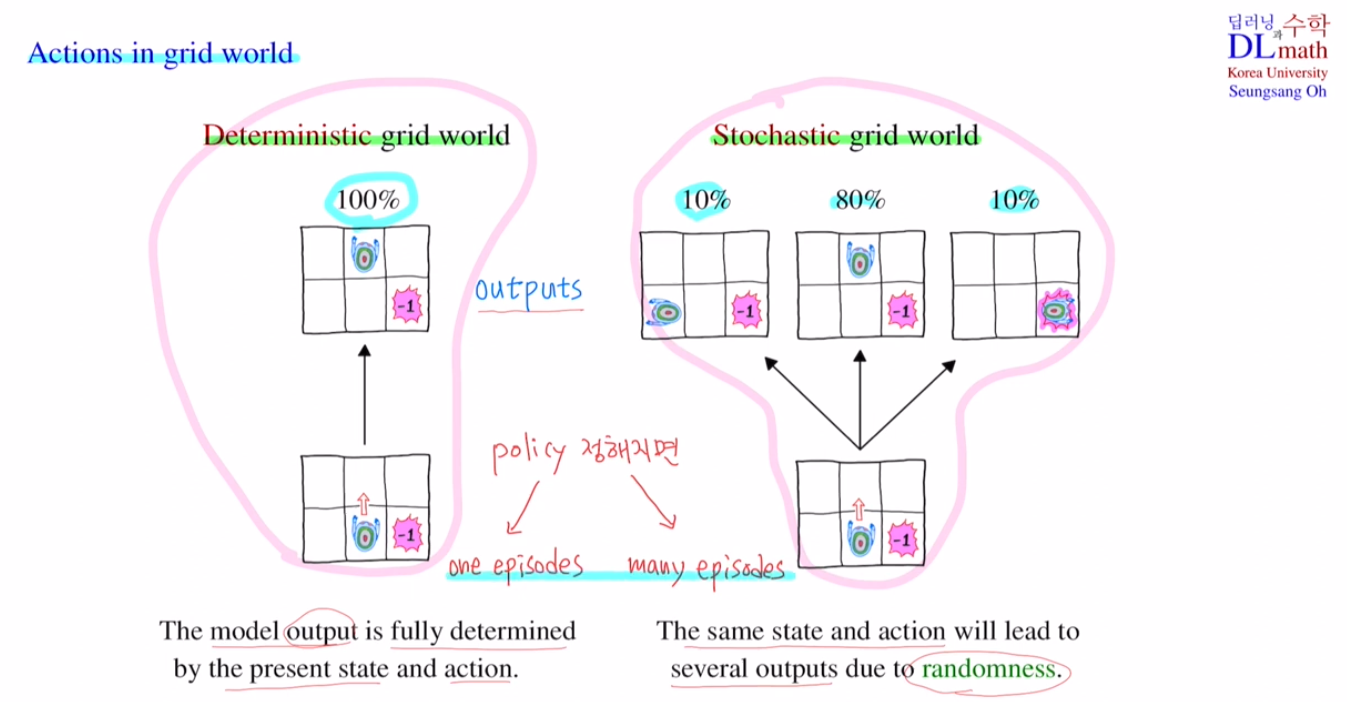
2-1. 결정적 전이(Deterministic transition)
- 모델의 output은 현재 state와 action에 의해 전적으로 좌우된다.
- 즉, noise 없이 action을 취한 방향으로 100% 이동한다.
- deterministric transition 방식으로 policy를 수립하면, 각 state마다 어떤 action을 취해야 할지가 정해져 있고, 실제로 그 action대로만 움직이기 때문에 policy에 의해 나올 수 있는 episode는 단 한 가지 이다.
2-2. 확률적 전이(Stochastic transition)
- 무작위성(randomness) 때문에 동일한 state와 action이 여러 가지 output으로 이어질 수 있다.
- e.g. north(80%), west(10%), east(10%)
- Stochastic transition 방식으로 policy를 수립하면, 각 state 마다 어떤 action을 취해야 할지가 정해져 있다 하더라도, 실제 게임이 진행되는 동안에는 계획과 다른 action을 취할 수 있다. 따라서, policy에 의해 나올 수 있는 episode는 여러 가지가 될 수 있다.
⇒ 대부분의 RL model에서는 stochastic transition을 사용한다.
3. Markov property
Markov decision process의 핵심인 Markov property에 대해 알아보자. 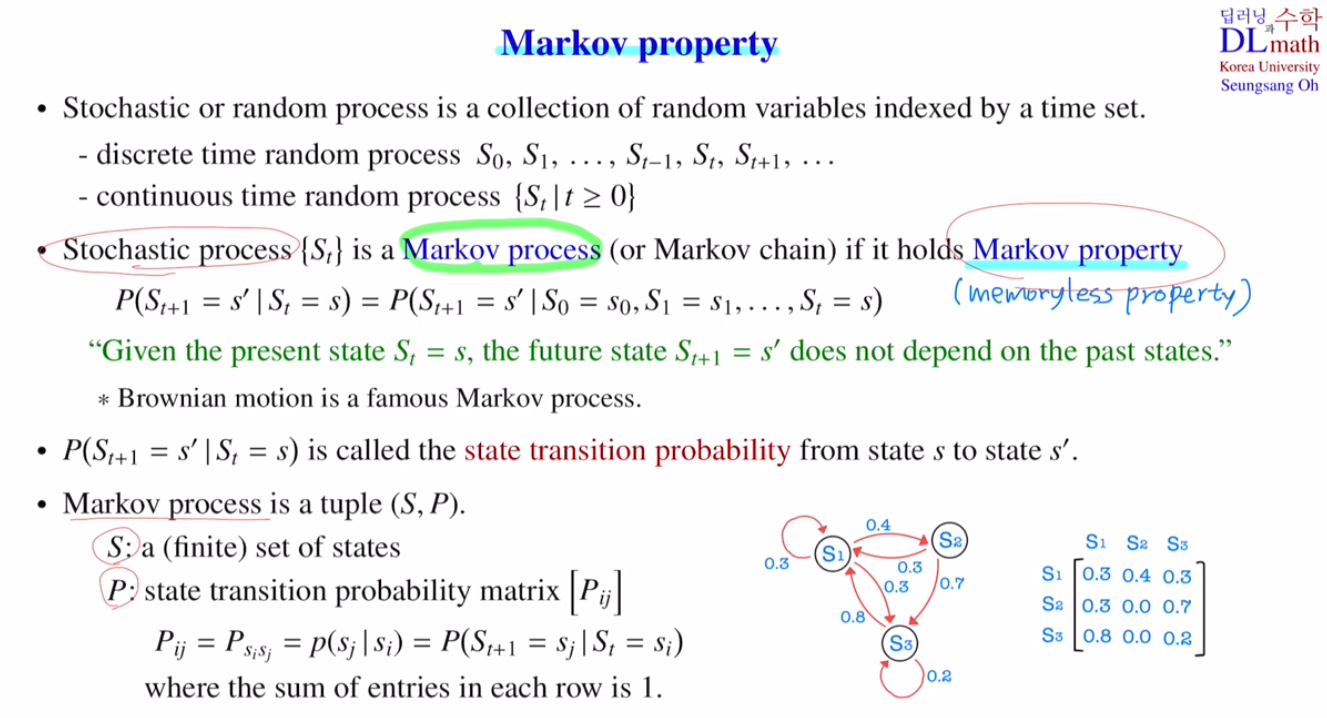
3-1. Stochastic process(or Random process)
- time set을 index로 갖는 확률 변수(random variable)들의 집합
- 강화학습에 random variable은 state($S$)를 의미한다.
이산 시간에 대한 랜덤 프로세스(Discrete time random process, 이산 확률 과정)
- $S_0, \ S_1, \ S_2 \ , \ \cdots \ , \ S_{t-1}, \ S_{t}, \ S_{t+1}$
| 현재 state | $S_t$ |
| 다음 state | $S_{t+1}$ |
| 과거 state | $S_0, \ S_1, \ S_2 \ , \ \cdots \ , \ S_{t-1}$ |
연속 시간에 대한 랜덤 프로세스(Continuous time randome process, 연속 확률 과정)
- $\left\lbrace S_t \mid t \geq 0 \right\rbrace$
3-2. Markov property
Markov property
\[P(S_{t+1}=s^{\prime} \ | \ S_t=s)= P(S_{t+1}=s^{\prime} \ | \ S_0=s_0, \ S_1=s_1, \ \dots \ ,S_t=s)\]
현재 state가 $S_t=s$ 일 때, 미래 state $S_{t+1}=s^{\prime}$ 는 과거 state에 의존하지 않는다.
즉, 과거 state의 영향과는 별개로 $S_t=s$ 에서 $S_{t+1}=s^{\prime}$ 로 갈 확률은 항상 일정하다.
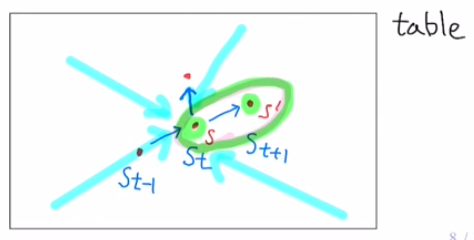
테이블 위에 어떠한 물체가 등속 운동을 하고 있다고 가정할 때,
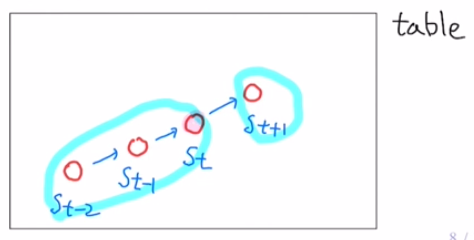
- 관성의 법칙에 의해 물체의 과거 위치($S_0, \ S_1, \ S_2 \ , \ \cdots \ , \ S_{t-1}$)를 알고 있다면 미래의 위치($S_{t+1}$) 또한 쉽게 알 수 있을 것이다.
- 만약, 현재 위치($S_t$)만 알고 있다면, 미래의 위치($S_{t+1}$)를 알아내는 것을 쉽지 않을 것이다. 왜냐하면 미래의 위치($S_{t+1}$)는 현재 위치($S_t$) 뿐만 아니라 과거 위치($S_0, \ S_1, \ S_2 \ , \ \cdots \ , \ S_{t-1}$)에도 영향을 받기 때문이다.
물체의 질량이 0에 가깝다고 가정할 때,
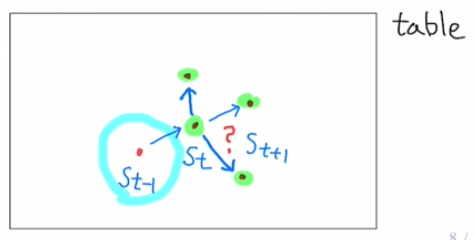
- 이는 질량을 무시해도 되는 수준이므로 관성의 법칙이 작용하지 않는다.
- 따라서, 미래의 위치($S_{t+1}$)는 더 이상 과거 위치($S_{t-1}$)에 영향을 받지 않게 된다. (Brownian motion)
브라운 운동(Brownian motion)
- 이는 1872년 스코틀랜드 식물학자 Robert Brown이 발견한 액체나 기체 속에서 미소 입자들이 불규칙하게 운동하는 현상이다. 수학 분야에서는 Random Walk로 모델링 될 수 있다.
- Brawnian motion은 잘 알려진 Markov process 이다.
3-3. State transition probability
\[P(S_{t+1}=s^{\prime} \ | \ S_t=s)\]- 현재 상태 $s$ 가 주어졌을 때, 다음 상태가 $s^{\prime}$ 으로 전이될 확률
3-4. Markov process
- Markov property를 만족하는 Stochastic process ${ S_t }$를 Markov process (또는 Markov chain)라고 부른다.
- Markov property를 만족한다면 과거 state를 기록하지 않아도 된다. (memoryless property)
Markov property를 만족하지 않는다면?
- $P(S_{t+1}=s^{\prime} \mid S_t=s)$ 를 계산한다고 할 때, Markov property를 만족하지 않는다면, 과거 state가 영향을 미치기 때문에 process가 진행되는 과정에서 과거 state들을 모두 기록해 두어야 한다.
- 조건부 확률 $P(S_{t+1}=s^{\prime} \mid S_0=s_0, S_1=s_1, \dots, S_t=s)$을 계산한다는 것은 어렵고 방대한 계산을 필요로 한다.
Markov process 구성 요소
\[P_{ij}=P_{s_{i}s_{j}}=p(s_j|s_i) =P(S_{t+1}=s_j|S_t=s_i)\]$S$ : a (finite) set of state
$P$ : state transition probability matrix, where $P = [P_{ij}]$
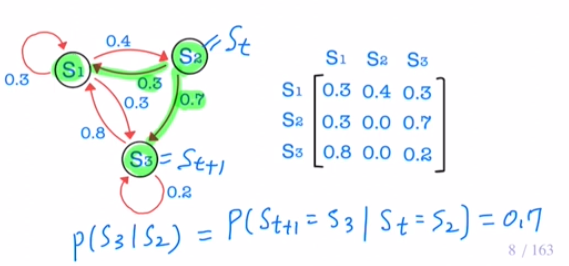
각 entry에 대한 state transition propability
- 상태 전이 확률 matrix의 각 행(row)에서의 원소들의 합(sum of entries)는 항상 1 이다.
Reference
https://www.youtube.com/watch?v=EtSNMoM97-k&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=2